MongoDB 是一款基于分布式文件存储的NoSQL数据库系统,由 MongoDB Inc. 开发(现属于 MongoDB 公司),于 2009 年开源,旨在为海量非结构化数据提供高效、灵活的存储与查询解决方案。
基础
核心概念
- 文档(Document):数据存储的基本单位,类似 JSON 格式,支持嵌套结构。与Mysql中的行对应。
- 集合(Collection):一组文档的 集合,无固定模式。与Mysql中的表对应。
- 数据库(Database):多个集合的逻辑分组,默认包含admin、local等系统库。与Mysql中的库对应。
优势
- 灵活的 Schema:无需预先定义表结构,支持动态字段。
- 高扩展性:通过分片(Sharding)实现水平扩展,支持 PB 级数据。
- 高性能:内存映射存储引擎(WiredTiger)优化读写性能。
服务安装与配置
参考文档:
数据库操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
show dbs;
db;
use <dbname>;
show tables;
show collections;
db.dropDatabase();
|
集合操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
db.cretaeCollection(name, options);
db.createCollection('collection_name', {capped: true, size : 100});
db.adminCommand({
renameCollection: "sourceDb.sourceCollection",
to: "targetDb.targetCollection",
dropTarget: <boolean>
})
db.collection_name.drop();
|
| 选项名 |
类型 |
默认值 |
生效版本 |
可使用的值 |
核心用途 |
| capped |
布尔值 |
false |
1.0+ |
true(固定集合) / false(普通集合) |
固定集合开关 |
| size |
数值 |
- |
1.0+ |
正整数(字节,需为 256 的倍数,如 1024(1KB)) |
固定集合大小(字节) |
| max |
数值 |
- |
1.0+ |
正整数(文档数量,如 1000) |
固定集合最大文档数 |
| validator |
文档 |
- |
2.2+ |
JSON Schema 文档(例:{ $jsonSchema: { bsonType: "object", ... } }) |
文档验证规则 |
| validationLevel |
字符串 |
moderate |
3.2+ |
off(不验证) / moderate(仅验证新文档) / strict(验证所有文档) |
验证级别 |
| indexOptionDefaults |
文档 |
{} |
3.2+ |
索引配置对象(例:{ expireAfterSeconds: 86400, sparse: true }) |
索引默认选项 |
| timeseries |
文档 |
- |
4.2+ |
{ timeField: "ts", metaField: "device", granularity: "seconds" } |
时间序列集合配置 |
| viewOn |
字符串 |
- |
5.0+ |
现有集合名(如 “orders”) |
创建视图 |
| collation |
文档 |
服务器默认 |
3.4+ |
语言配置对象(例:{ locale: "zh_CN", strength: 2 }) |
语言排序规则 |
| autoIndexId |
布尔值 |
true |
3.6+ |
true(自动创建 _id 索引) / false(手动管理) |
自动创建 _id 索引 |
数据类型
| 分类 |
类型 |
支持版本 |
含义 |
典型场景 |
注意事项 / 示例 |
| 基础数据类型 |
String |
≥ 1.0 |
UTF-8 字符串(BSON 最大 16MB) |
用户名、描述 |
“hello world” |
|
Integer (Int64) |
≥ 2.2(默认) |
64 位整数(±9e18) |
年龄、用户 ID(如1234567890123) |
2.2 前为 Int32(±2^31-1) |
|
Boolean |
≥ 1.0 |
布尔值 |
开关状态(is_active: true) |
|
|
Double |
≥ 1.0 |
64 位浮点数 |
价格、经纬度(9.99/[116.40, 39.90]) |
|
|
Date |
≥ 1.0 |
日期时间(Unix 毫秒时间戳) |
创建时间(new Date("2025-04-14")) |
|
|
Null |
≥ 1.0 |
显式空值(区别于字段不存在) |
可选未设置字段(email: null) |
db.col.find({ field: null }) 匹配null或字段不存在,需用$exists精确过滤 |
| 复合数据类型 |
Array |
≥ 1.0 |
任意类型混合数组 |
标签、多值属性(["reading", 28]) |
|
|
Document |
≥ 1.0 |
嵌套文档(支持深度嵌套) |
地址({ addr: { city: "Beijing" } }) |
|
|
ObjectId |
≥ 1.0 |
文档唯一 ID(12 字节,含时间戳 + 机器 ID) |
主键(_id默认类型) |
自动生成含时间戳,按时间插入可优化索引 |
|
Map |
≥ 5.0 |
键值对映射(优化动态字段查询) |
配置参数({ "key1": "value1" }) |
查询需引号包裹键名({ "map.key": "value" }) |
| 特殊数据类型 |
Regex |
≥ 1.0 |
PCRE 正则表达式 |
邮箱格式校验(/^\\w+@\\w+\\.com$/) |
谨慎使用,可能导致全表扫描 |
|
DBPointer |
≥ 1.0(弃用) |
跨集合文档引用(如{ $ref: "users", $id: ObjectId("...") }) |
历史系统跨集合关联 |
3.6+ 推荐$lookup聚合替代 |
|
MinKey/MaxKey |
≥ 1.0 |
范围查询边界占位符 |
索引优化({ age: { $lt: MaxKey } }) |
仅用于查询,不可存储为文档值 |
| 二进制/高精度 |
Binary Data |
≥ 1.0 |
二进制数据(如图片、文件) |
存储缩略图(BinData(0, "base64...")) |
|
|
UUID |
≥ 3.4 |
全局唯一 ID(binary subtype 4) |
设备 ID(UUID("123e4567-e89b...")) |
需驱动支持(如 Python bson.uuid.UUID) |
|
Decimal128 |
≥ 2.6(稳定≥3.4) |
高精度十进制(避免浮点误差) |
金融金额(Decimal128("1000.01")) |
2.6-3.4 为实验性,需显式声明$decimal128 |
| 已弃用类型 |
Symbol |
≤ 3.6(废弃) |
早期字符串类型(用于系统集合) |
无 |
迁移为String |
|
Code |
≤ 4.4(废弃) |
存储 JavaScript 代码 |
无 |
安全风险高,改用应用层逻辑 |
文档操作
插入
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
db.collection.insertOne(document, options);
db.users.insertOne({
username: "user1",
email: "user1@example.com",
created_at: new Date()
});
db.collection.insertMany(documents, options);
db.users.insertMany([
{ username: "user2", email: "user2@example.com" },
{ username: "user3", email: "user3@example.com" }
]);
|
| 选项名 |
类型 |
默认值 |
可使用值范围 |
生效版本 |
核心用途(关键差异) |
适用方法 |
| writeConcern |
文档/字符串 |
实例默认值 |
w: 0//“majority”, wtimeout(毫秒) |
3.2+ |
共有:insertOne 单文档确认;insertMany 整体/部分确认(依赖 ordered) |
共有 |
| bypassDocumentValidation |
布尔 |
false |
true(跳过集合验证) |
3.2+ |
共有:两方法均跳过 validator 校验(谨慎使用) |
共有 |
| session |
事务会话对象 |
null |
有效的事务会话(ClientSession 实例) |
4.0+ |
共有:insertMany 支持事务内原子化批量操作 |
共有 |
| comment |
字符串 / 文档 |
null |
任意可序列化值(如{ tag: "bulk" }) |
4.4+ |
共有:标注操作(审计 / 监控可见) |
共有 |
| let |
文档 |
{} |
变量绑定(如 { today: ISODate() }) |
5.0+ |
共有:供 collation 或表达式使用 |
共有 |
| ordered |
布尔 |
true |
true(按序插入,失败即停) / false(并行插入,忽略部分错误) |
2.6+ |
insertMany 特有:控制批量插入的顺序性与错误策略(insertOne 无此概念) |
insertMany |
| maxDocs |
数值 |
0 |
正整数(分片集群限制单次插入文档数,如 10000) |
5.0+ |
insertMany 特有:防止超大批次导致分片压力(insertOne 固定为 1 条) |
insertMany |
| continueOnError |
布尔 |
false |
(已废弃,改用 ordered: false) |
3.2-4.2 |
insertMany 特有(旧):旧版兼容选项,新版通过 ordered: false 实现 |
insertMany |
更新
1
2
3
4
5
6
7
8
9
10
11
12
13
|
db.collection.updateOne(filter, update, options);
db.users.updateOne(
{ username: "user1" },
{ $set: { status: "inactive" }, $inc: { points: 10 } }
);
db.collection.updateMany(filter, update, options)
db.users.updateMany(
{ role: "admin" },
{ $set: { permissions: ["read", "write"] } }
);
|
| 选项名 |
类型 |
默认值 |
可使用值范围 |
生效版本 |
核心用途(关键差异) |
适用方法 |
| writeConcern |
文档 / 字符串 |
实例默认值 |
w: 0//“majority”, wtimeout(毫秒) |
3.2+ |
共有:updateOne 单文档确认;updateMany 批量确认(受 arrayFilters 影响) |
共有 |
| bypassDocumentValidation |
布尔 |
false |
true(跳过集合验证) |
3.2+ |
共有:跳过更新后的文档校验(如临时修改敏感字段) |
共有 |
| session |
事务会话对象 |
null |
有效的事务会话(ClientSession 实例) |
4.0+ |
共有:updateMany 支持事务内批量原子操作(如批量扣减库存) |
共有 |
| comment |
字符串 / 文档 |
null |
任意可序列化值(如{ tag: "bulk_update" }) |
4.4+ |
共有:标注操作(审计 / 监控可见,如 “promotion_price”) |
共有 |
| let |
文档 |
{} |
变量绑定(如 { discount: 0.8 },供更新表达式使用) |
5.0+ |
共有:临时变量在 update 表达式中复用(如$expr: { $gte: ["$price", "$$discount"] }) |
共有 |
| upsert |
布尔 |
false |
true(不存在则插入) / false |
2.6+ |
共有:updateOne 插入单文档;updateMany 按条件插入多条(慎用!可能批量创建) |
共有 |
| arrayFilters |
数组 |
[] |
过滤数组元素的条件(如[{ "elem.status": "active" }]) |
3.6+ |
updateMany 特有:批量更新数组内元素,精准控制更新目标 |
updateMany |
| hint |
文档 / 字符串 |
null |
索引键或名称(如 { user_id: 1 },分片键索引优先) |
3.2+ |
共有:updateMany 强制使用索引优化批量操作(避免全表扫描) |
共有 |
| collation |
文档 |
服务器默认 |
语言排序规则(如{ locale: "zh", strength: 2 }) |
3.4+ |
共有:影响字符串比较(如 $eq、$gt),updateMany 批量应用相同规则 |
共有 |
删除
1
2
3
4
5
6
7
8
9
10
11
|
db.collection.deleteOne(filter, options);
db.users.deleteOne({ username: "user1" });
db.collection.deleteMany(filter, options);
db.users.deleteMany({ status: "deleted" });
db.collection.findOneAndDelete(filter, options);
db.users.findOneAndDelete({ status: "deleted" });
|
| 选项名 |
类型 |
默认值 |
可使用值范围 |
生效版本 |
核心用途(关键差异) |
适用方法 |
| writeConcern |
文档 / 字符串 |
实例默认值 |
w: 0//“majority”, wtimeout(毫秒) |
3.2+ |
共有:deleteOne 单文档确认;deleteMany 批量确认;findOneAndDelete 事务内确认 |
共有 |
| session |
事务会话对象 |
null |
有效的事务会话(ClientSession 实例) |
4.0+ |
共有:findOneAndDelete 支持事务内原子化查询 + 删除 |
共有 |
| comment |
字符串 / 文档 |
null |
任意可序列化值(如{ tag: "cleanup" }) |
4.4+ |
共有:标注操作(如 “delete_old_logs”) |
共有 |
| collation |
文档 |
服务器默认 |
语言排序规则(如{ locale: "zh", strength: 2 }) |
3.4+ |
共有:影响查询条件的字符串比较(如 deleteOne 按拼音匹配删除) |
共有 |
| hint |
文档 / 字符串 |
null |
索引键或名称(如{ user_id: 1 },分片键索引优先) |
3.2+ |
共有:findOneAndDelete 强制索引优化查询路径;deleteMany 避免全表扫描 |
共有 |
| maxTimeMS |
数值 |
0(无限制) |
正整数(毫秒,如 5000) |
3.2+ |
共有:防止长时间运行(findOneAndDelete 常见于复杂查询场景) |
共有 |
| returnDocument |
字符串 |
“before” |
“before”(删除前文档) / “after”(删除后文档,仅空文档) |
3.2+ |
findOneAndDelete 特有:控制返回数据(deleteOne 无返回,deleteMany 批量无意义) |
findOneAndDelete |
| sort |
文档 |
{} |
排序键(如 { created_at: -1 }) |
3.2+ |
findOneAndDelete 特有:指定删除优先级(如删除最新文档) |
findOneAndDelete |
| projection |
文档 |
{} |
字段投影(如{ username: 1, _id: 0 }) |
3.2+ |
findOneAndDelete 特有:控制返回文档的字段(deleteOne/deleteMany 无返回) |
findOneAndDelete |
| let |
文档 |
{} |
变量绑定(如{ expire: ISODate("2025-01-01") }) |
5.0+ |
共有:供查询条件中的$expr使用(如 deleteMany 按变量过滤) |
共有 |
文档简单查询
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
db.collection.find(query, projection);
db.users.find({ username: "user1" });
db.users.find({ age: { $gt: 30 }, status: "active" });
db.users.find({ active: true }, { username: 1, email: 1 });
db.collection.find().sort({field1:1,field2:-1}).skip(<skip>).limit(<limit>);
db.collection.findOne(query, projection);
|
高级语法
过滤条件
1
2
3
4
5
|
db.collection.find(query, projection);
db.collection.deleteOne(filter, options);
db.collection.updateOne(filter, update, options);
db.col.find({"likes": {$gt:50}, $or: [{"by": "test"},{"title": "教程"}]}).pretty();
|
- 查询运算符(find/delete/update 过滤条件)
| 分类 |
运算符 |
语法示例 |
核心用途 |
生效版本 |
| 基础比较 |
$eq |
{ age: { $eq: 30 } } |
等于(可省略,直接 { age: 30 }) |
1.0+ |
|
$ne |
{ status: { $ne: "closed" } } |
不等于 |
1.0+ |
|
$gt/$gte |
{ score: { $gt: 80 } } |
大于 / 大于等于 |
1.0+ |
|
$lt/$lte |
{ price: { $lte: 100 } } |
小于 / 小于等于 |
1.0+ |
| 范围查询 |
$in |
{ category: { $in: ["A", "B"] } } |
字段值在数组中 |
1.0+ |
|
$nin |
{ tags: { $nin: ["spam"] } } |
字段值不在数组中 |
1.0+ |
| 逻辑组合 |
$and |
{ $and: [{ age: { $gt: 18 } }, { status: "active" }] } |
多条件同时满足(可省略,直接逗号分隔) |
1.0+ |
|
$or |
{ $or: [{ age: { $lt: 13 } }, { age: { $gt: 65 } }] } |
任一条件满足 |
1.0+ |
|
$not |
{ email: { $not: /@example\.com/ } } |
取反(支持正则 / 表达式) |
2.2+ |
| 类型检查 |
$type |
{ field: { $type: "string" } } |
检查字段类型(”string”/“objectId” 等,或数字代码如 2 表示字符串) |
2.2+ |
| 正则匹配 |
$regex |
{ username: { $regex: "^user" } } |
正则表达式匹配(支持i不区分大小写,m多行) |
1.0+ |
| 存在性 |
$exists |
{ email: { $exists: true } } |
字段存在(true 存在,false 不存在) |
1.0+ |
更新操作
1
2
3
4
5
6
|
db.collection.updateOne(filter, update, options);
db.collection.updateOne(
{ name: "Alice" },
{ $set: { age: 26 }, $addToSet: { habits: ""}, $push: { like: "ball" } }
);
|
- 更新运算符(updateOne/updateMany 操作)
| 分类 |
运算符 |
语法示例 |
核心用途 |
生效版本 |
| 赋值 |
$set |
{ $set: { "profile.name": "Alice" } } |
设置字段值(支持嵌套路径) |
1.0+ |
|
$unset |
{ $unset: { "profile.age": "" } } |
删除字段(值可为任意非空,通常用 “”) |
1.0+ |
| 增减 |
$inc |
{ $inc: { balance: -100 } } |
数值增减(支持负数,原子操作) |
1.0+ |
| 数组 |
$push |
{ $push: { tags: "new_tag" } } |
向数组添加元素(支持 $each 批量添加,$position 指定位置) |
1.0+ |
|
$pull |
{ $pull: { tags: "old_tag" } } |
从数组删除匹配元素(按值删除) |
1.0+ |
|
$addToSet |
{ $addToSet: { tags: "unique_tag" } } |
数组去重添加(仅新增不存在的元素) |
2.2+ |
| 条件更新 |
$min/$max |
{ $min: { low_score: 60 } } |
仅当新值更小时更新($min)/ 更大时更新($max) |
2.6+ |
| 表达式 |
$expr |
{ $set: { discount: { $expr: { $multiply: ["$price", 0.8] } } } } |
内联表达式(需配合 let 变量) |
3.6+ |
聚合查询
管道在Unix和Linux中一般用于将当前命令的输出结果作为下一个命令的参数。
MongoDB的聚合管道将MongoDB文档在一个管道处理完毕后将结果传递给下一个管道处理。管道操作是可以重复的。
表达式:处理输入文档并输出。表达式是无状态的,只能用于计算当前聚合管道的文档,不能处理其它的文档。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
|
db.collection.aggregate([
{管道1: {表达式1}},
{管道2: {表达式2}},
{管道3: {表达式3}}
]);
db.articles.aggregate([
{ $match : { score : { $gt : 70, $lte : 90 } } },
{ $group: { _id: null, count: { $sum: 1 } } }
]);
db.collection_name.aggregate(
{$group:
{
_id : '$字段名', //根据某个字段进行分组 group by field
别名 : {聚合函数:'$字段名'} //计算的数据
}
}
);
db.collection_name.aggregate(
{$group: {
_id:'$name',
'total_age':{$sum:'$age'}
}}
);
db.collection_name.aggregate(
{$group: {
_id:null,
"平均年龄":{$avg:'$age'},
"数据条数":{$sum:1}
}}
);
db.collection_name.aggregate(
{$group: {
_id : '$sex',
'count' : {$sum:1},
"名单" : {$push:'$name'}
}}
);
db.collection_name.aggregate({
$group:{
_id:'$sex',
"小组第一个人":{$first:'$name'},
"小组最后一个人":{$last:'$name'}
}
});
db.collection_name.aggregate({
$match:{"age":{$gt:30}}
});
db.collection_name.aggregate([
{$match:{"age":{$gt:30}}},
{$group:{_id:null, 'count':{$sum:1}}}
]);
db.collection_name.aggregate({
$project:{"_id":0, "name":1,"sex":0,"age":1}
});
db.collection_name.aggregate({
$sort: {
"age":1
}
});
db.collection_name.aggregate([
{$sort:{"age":1}},
{$limit:10},
{$skip:10}
]);
db.users.aggregate([
{$match:{"data":{$exists:true}}},
{$unwind:"$data"}
]);
|
| 分类 | 运算符 | 语法示例 | 核心用途 | 生效版本 |
|—|—|—|—|—|—|
| 文档操作 | $project | { $project: { name: 1, _id: 0 } } | 投影字段(1 包含,0 排除) | 1.5+ |
| | $match | { $match: { status: "active" } } | 过滤文档(等价于 find 的条件) | 1.5+ |
| 分组统计 | $group | { $group: { _id: "$category", total: { $sum: 1 } } } | 按字段分组,聚合计算($sum/$avg/$first 等) | 1.5+ |
| 数组处理 | $unwind | { $unwind: "$hobbies" } | 展开数组为单独文档(path 字段名,preserveNullAndEmptyArrays 控制空数组) | 2.2+ |
| 排序分页 | $sort | { $sort: { created_at: -1 } } | 排序(1 升序,-1 降序) | 1.5+ |
| | $limit | { $limit: 10 } | 限制结果数量 | 1.5+ |
| 表达式 | $lookup | { $lookup: { from: "orders", localField: "user_id", foreignField: "user_id", as: "user_orders" } } | 左外连接(类似 SQL JOIN) | 3.2+ |
其他运算符
| 运算符 |
语法示例 |
核心用途 |
生效版本 |
| $all |
{ tags: { $all: ["tech", "guide"] } } |
数组包含所有元素(顺序无关) |
1.3+ |
| $elemMatch |
{ scores: { $elemMatch: { $gte: 80, $lt: 90 } } } |
数组中存在至少一个元素满足条件 |
2.2+ |
| $size |
{ tags: { $size: 5 } } |
数组长度等于指定值 |
3.2+ |
| $[] |
{ $set: { "array.$[id].status": "done" } },配合 arrayFilters |
批量更新数组指定元素(需 updateMany) |
3.6+ |
| $geoNear |
{ $geoNear: { near: [lon, lat], distanceField: "dist" } } |
聚合管道中查找附近文档(需索引) |
2.4+ |
| $geoWithin |
{ location: { $geoWithin: { $center: [[lon, lat], 1000] } } } |
文档在圆形 / 多边形范围内 |
2.4+ |
| $near |
{ location: { $near: [lon, lat], $maxDistance: 1000 } } |
查询附近文档(find 方法,需 2d 索引) |
2.2+ |
| $eval |
{ $eval: "function() { return db.collection.find().limit(1); }" } |
执行 JS 代码(不推荐,4.4+ 需开启 allowEvaluate) |
1.0+ |
| $jsonSchema |
{ $jsonSchema: { bsonType: "object", required: ["email"] } } |
文档验证(createCollection 的 validator 选项) |
3.2+ |
| $lookup |
见聚合运算符部分 |
- |
- |
索引管理
索引分类
在 MongoDB 中,常见的索引类型包括:
- 单字段索引:基于单个字段的索引。
- 复合索引:基于多个字段组合的索引。
- 文本索引:用于支持全文搜索。
- 地理空间索引:用于地理空间数据的查询。
- 哈希索引:用于对字段值进行哈希处理的索引。
索引操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| -- 创建索引
-- keys:一个对象,指定了字段名和索引的排序方向(1 表示升序,-1 表示降序)。
-- options:一个可选参数,可以包含索引的额外选项。
db.collection.createIndex(keys, options);
-- 创建 age 字段的升序索引
db.myCollection.createIndex({ age: 1 });
-- 创建 name 字段的文本索引
db.myCollection.createIndex({ name: "text" });
-- 创建hash索引
db.collection.createIndex( { field: "hashed" } );
-- 删除索引
db.collection.dropIndex( "indexName" );
-- 删除所有索引
db.collection.dropIndexes();
|
| Option Key |
支持版本 |
含义 |
可选值 / 类型 |
使用场景 |
| background |
≥ 2.6 |
后台创建索引(不阻塞读写) |
true/false(默认false) |
生产环境避免锁表(如用户量百万级集合创建索引) |
| unique |
≥ 2.0 |
确保字段值唯一 |
true/false |
用户邮箱、身份证号等唯一标识字段(需配合sparse忽略缺失值) |
| name |
≥ 2.0 |
自定义索引名称 |
字符串(默认自动生成) |
复杂索引管理(如user_age_status_idx便于运维排查) |
| sparse |
≥ 2.2 |
仅索引存在的字段(忽略缺失值) |
true/false |
可选字段(如用户last_login_time,非必填时节省 50%+ 索引空间) |
| expireAfterSeconds |
≥ 2.2 |
TTL 索引(自动过期文档) |
数字(≥0,秒) |
日志、缓存类数据(如用户会话记录,设置 24 小时过期) |
| partialFilterExpression |
≥ 3.2 |
部分索引(仅包含符合条件的文档) |
MongoDB 查询表达式 |
高频查询子集(如status: “active”的订单,索引大小减少 70%) |
| collation |
≥ 3.4 |
自定义排序规则(语言 / 大小写 / 重音) |
Collation 对象 |
多语言场景(如中法双语系统的name字段排序) |
| hidden |
≥ 5.0 |
隐藏索引(不被优化器自动使用) |
true/false |
测试新索引性能(需手动hint(),避免干扰现有查询) |
| 2dsphere |
≥ 2.4 |
地理空间索引(经纬度) |
配置对象(如sphereVersion) |
位置服务(如附近的餐厅搜索,需loc字段为[经度, 纬度]数组) |
| textIndexVersion |
≥ 3.2 |
文本索引版本(提升分词能力) |
1或2(默认1) |
复杂搜索(如电商商品description字段,version 2支持短语高亮) |
| weights |
≥ 2.6 |
文本索引字段权重(影响相关性) |
对象(字段:权重) |
内容平台(如文章title权重 3,content权重 1,优先匹配标题) |
| default_language |
≥ 2.6 |
文本索引默认语言(分词规则) |
语言代码(如”chinese”) |
非英语场景(中文需额外安装cjk分词器,否则默认按拼音分词) |
| writeConcern |
≥ 2.6 |
索引创建时的写入一致性 |
WriteConcern 对象 |
金融场景(如w: “majority”确保多数节点确认,避免索引不一致) |
| dropDups |
≤ 3.0 |
已弃用:删除重复文档创建唯一索引(改用unique: true) |
true/false |
无(3.0 + 强制报错,直接使用unique) |
| storageEngine |
≤ 3.4 |
已弃用:指定索引存储引擎(3.4 + 统一 WiredTiger) |
字符串(如”mmapv1”) |
无(新版本忽略) |
数据库安全
- 首先以无密码形式登录
- 创建管理员密码,
use admin;
- 添加一个超级管理员
db.createUser({user:"admin",pwd:"password",roles:["root"]});
- 验证密码(必须在admin库下才能正常执行)
db.auth('admin', 'password');
- 重启mongodb服务(不单单只是重启,如果安装了windows的服务,需要重新安装windows服务)
- 关闭mongo服务,然后重新启动
mongod --dbpath "d:\mongodb\db\" --logpath "d:\mongo\log\mongo.log" --auth
- 注意的点:
- 如果安装了MongoDB的windows服务,需要先卸载windows服务
- 需要确定windows服务的名称是否为mongodb
1
2
3
4
5
6
| net stop mongodb
sc delete mongodb
//注意,开启了验证用户身份(--auth)匿名用户仍然可以登录,但是不能查询、操作任何数据。
mongod --dbpath "d:\mongodb\db\" --logpath "d:\mongo\log\mongo.log" --install --serviceName "MongoDB" --auth
//为某个库添加指定的管理员,添加的管理员只能访问某个库
db.createUser({user:"root",pwd:"root", roles:[role:"dbOwner", db:"db_name"]});
|
常用组件
副本集
什么是副本集
MongoDB副本集是将数据同步在多个服务器的过程。
副本集提供了数据的冗余备份,并在多个服务器上存储数据副本,提高了数据的可用性, 并可以保证数据的安全性。
副本集还允许您从硬件故障和服务中断中恢复数据。

副本集的特征
- N 个节点的集群
- 任何节点可作为主节点
- 所有写入操作都在主节点上
- 自动故障转移
- 自动恢复
如何设置副本集
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
mongod --port "PORT" --dbpath "YOUR_DB_DATA_PATH" --replSet "REPLICA_SET_INSTANCE_NAME"
mongod --port 27017 --dbpath "D:\set up\mongodb\data" --replSet rs0
rs.initiate();
rs.conf();
rs.status();
rs.add(HOST_NAME:PORT)
rs.add("mongod1.net:27017")
|
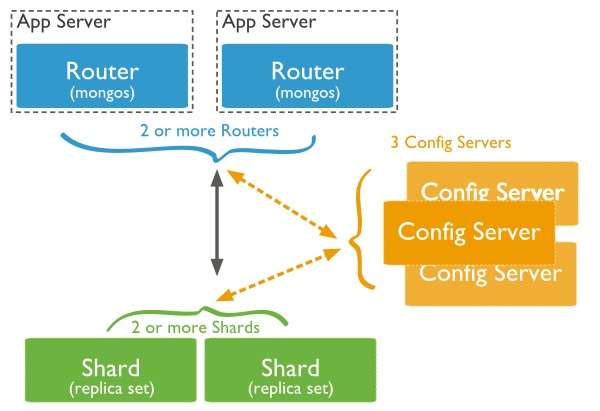
Mongos(分片路由进程)
在Mongodb里面存在另一种集群,就是分片技术,可以满足MongoDB数据量大量增长的需求。
当MongoDB存储海量的数据时,一台机器可能不足以存储数据,也可能不足以提供可接受的读写吞吐量。这时,我们就可以通过在多台机器上分割数据,使得数据库系统能存储和处理更多的数据。
图中主要有如下所述三个主要组件:
- Shard:
用于存储实际的数据块,实际生产环境中一个shard server角色可由几台机器组个一个replica set承担,防止主机单点故障
- Config Server:
mongod实例,存储了整个 ClusterMetadata,其中包括 chunk信息。
- Query Routers:
前端路由,客户端由此接入,且让整个集群看上去像单一数据库,前端应用可以透明使用。
为什么使用分片
- 复制所有的写入操作到主节点
- 延迟的敏感数据会在主节点查询
- 单个副本集限制在12个节点
- 当请求量巨大时会出现内存不足。
- 本地磁盘不足
- 垂直扩展价格昂贵
如何设置Mongos
分片结构端口分布如下:
1
2
3
4
5
6
| Shard Server 1:27020
Shard Server 2:27021
Shard Server 3:27022
Shard Server 4:27023
Config Server :27100
Route Process:40000
|
1
2
3
4
5
6
7
8
| [root@100 /]# mkdir -p /www/mongoDB/shard/s0
[root@100 /]# mkdir -p /www/mongoDB/shard/s1
[root@100 /]# mkdir -p /www/mongoDB/shard/s2
[root@100 /]# mkdir -p /www/mongoDB/shard/s3
[root@100 /]# mkdir -p /www/mongoDB/shard/log
[root@100 /]# /usr/local/mongoDB/bin/mongod --port 27020 --dbpath=/www/mongoDB/shard/s0 --logpath=/www/mongoDB/shard/log/s0.log --logappend --fork
....
[root@100 /]# /usr/local/mongoDB/bin/mongod --port 27023 --dbpath=/www/mongoDB/shard/s3 --logpath=/www/mongoDB/shard/log/s3.log --logappend --fork
|
1
2
| [root@100 /]# mkdir -p /www/mongoDB/shard/config
[root@100 /]# /usr/local/mongoDB/bin/mongod --port 27100 --dbpath=/www/mongoDB/shard/config --logpath=/www/mongoDB/shard/log/config.log --logappend --fork
|
1
| /usr/local/mongoDB/bin/mongos --port 40000 --configdb localhost:27100 --fork --logpath=/www/mongoDB/shard/log/route.log --chunkSize 500
|
1
2
3
4
5
6
7
8
9
10
11
12
| [root@100 shard]# /usr/local/mongoDB/bin/mongo admin --port 40000
MongoDB shell version: 2.0.7
connecting to: 127.0.0.1:40000/admin
mongos> db.runCommand({ addshard:"localhost:27020" })
{ "shardAdded" : "shard0000", "ok" : 1 }
......
mongos> db.runCommand({ addshard:"localhost:27029" })
{ "shardAdded" : "shard0009", "ok" : 1 }
mongos> db.runCommand({ enablesharding:"test" })
{ "ok" : 1 }
mongos> db.runCommand({ shardcollection: "test.log", key: { id:1,time:1}})
{ "collectionsharded" : "test.log", "ok" : 1 }
|
- 程序代码内无需太大更改,直接按照连接普通的mongo数据库那样,将数据库连接接入接口40000