Go项目内存泄露的排查
项目逻辑介绍
本项目作为一个常驻后台服务,基于RabbitMQ消息队列构建了持续处理URL资源的流程,整体逻辑以“消息消费-资源处理-数据流转”为主线,具体如下:
- 首先,项目接收外部输入的 URL,基于该 URL 的特性完成一系列基础配置工作,包括代理策略配置(判断是否需要通过代理访问)、头部信息获取(提取 URL 的头部信息)以及资源类型预判(对 URL 指向的资源进行初步判断,如是否为可下载资源等)。
- 当目标资源支持分片下载时,项目会启动多协程分片下载机制:将资源按设定的分片规则分割并分别下载到内存中,随后在内存中完成分片数据的合并,从而得到完整的 URL 资源数据。
- 接着,将整合后的资源数据输入到扫描器。扫描器作为一个黑盒处理模块,内部实现了复杂的判断逻辑,能够根据不同类型的资源特性,输出相应的资源相关数据。
- 最后,项目会把获取到的资源数据推送到自有存储服务进行持久化存储,同时将 URL 与资源 MD5 值的映射关系推送到下游处理流程,以便后续业务环节对数据进行进一步处理和应用。
遇到BUG
项目上线运行一段时间后,观察到服务器内存使用率呈现持续攀升趋势。初步怀疑是下载流程中内存未完全释放,导致积压累积。然而 Go 语言内置的垃圾回收机制基于 “三原色标记法”,会自动管理内存生命周期,按常理不应出现内存泄漏问题,因此初期排查时将问题归因于服务器环境配置或外部依赖。
BUG排查
使用pprof分析
通过系统监控工具排查所有服务器进程后,最终定位到项目服务进程的内存占用呈持续增长态势。借助 pprof 工具链逐步分析内存分布时,发现大量内存空间泄漏在 Go 语言内置函数的调用路径中。作为 Go 语言的学习者,自然不会轻易怀疑其底层内存管理机制,因此决定从业务代码层入手,优先调整 “下载逻辑” 模块的实现方式,尝试解决内存持续增长的问题。

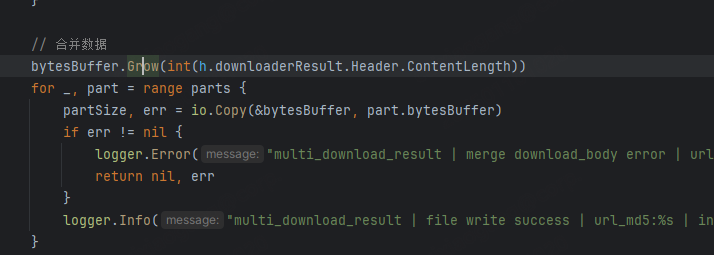
尝试受阻
完成代码调整并重启服务进行压测时,发现内存泄漏问题仍未得到解决。再次借助 pprof 工具剖析内存分布,虽然内存持续增长的趋势依旧存在,但泄漏的定位信息出现了显著变化 —— 内存占用的热点区域从 Go 语言内置函数转移到了自主实现的业务逻辑模块。

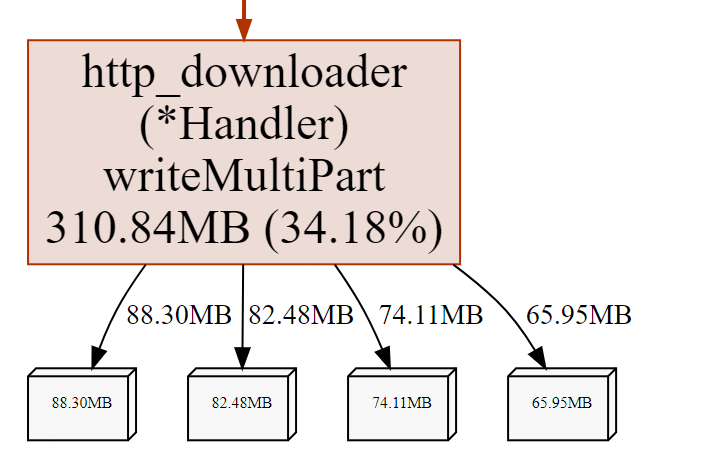
为排除多协程并发处理的干扰,本次测试采用单协程模式执行数据处理逻辑。通过 pprof 工具追踪内存分配时发现,目标函数作用域内依然出现了多个非预期的内存块实例 —— 按设计应仅存在当前分片下载的单个数据块。这一异常现象表明内存泄漏问题依然存在,且显然与业务逻辑中的资源管理逻辑相关。尽管已对业务代码中所有可优化的资源释放环节进行了调整,但仍未定位到具体泄漏点,不得不继续深入代码细节展开排查。
寻找新思路
深入研究 pprof 内存分析原理后意识到,内存泄漏的实际源头未必是 pprof 内存图直接标注的位置 —— 某些未被正确释放的资源引用可能通过对象生命周期传递,导致 GC 无法回收相关内存块。基于这一认知,开始排查 “扫描” 与 “上传” 流程中是否存在资源句柄或变量未释放的情况:由于 “上传” 模块使用统一封装的通用代码,初步判断问题概率较低,因此优先聚焦 “扫描” 逻辑展开细致检查。
发现曙光
进一步将“扫描”模块代码剥离并进行单元测试,发现该模块在独立运行时未复现内存泄漏问题。基于此,初步锁定问题可能存在于“上传”逻辑中。对“上传”模块进行单元测试剥离后,在持续压测时观察到偶发性内存增长现象 —— 当高频次调用“上传”接口时,内存块回收出现延迟累积。这一现象表明,“上传”模块的业务代码中存在非预期的资源持有逻辑,导致 GC 无法及时释放相关内存资源。
为精准捕捉异常,先对上传模块日志进行降噪处理,仅保留关键业务信息并输出至终端。同时开发自动化脚本,定时抓取 pprof 内存快照并生成动态内存分配图谱,通过 Web 服务实现页面实时刷新。在持续压测过程中,采用「日志时间戳与内存快照双维度关联」的分析策略:当脚本监测到内存图中出现第二个非预期分片数据块时,立即检索对应时间点的日志记录。这一过程中发现关键线索 —— 每当日志中出现某条特定的资源校验报错(如 MD5 值计算异常)时,内存分配图谱中就会新增一个未释放的数据块实例,初步锁定报错逻辑与内存泄漏存在直接关联。

解释一下这个错误,问题根源在于本地存储服务的去重校验机制:当多个客户端并发上传MD5值相同的资源时,服务端为处理分布式环境下的写竞争,会返回自定义错误码504(表示「去重校验中」)。此时客户端检测到资源可能已存在,但为避免因网络波动导致的上传丢失,遵循「最终一致性」原则持续发起重试,直至收到服务端明确返回的业务状态码101(标识「文件已存在」)。
问题解决
在代码审计中发现,重试逻辑中的资源释放语句从语法层面看已完整覆盖(如显式关闭文件句柄、归零切片引用等),理论上不应存在「句柄未释放」或「对象引用残留」问题。但在常规排查未定位到具体泄漏点的情况下,决定采用「代码重构验证法」——剥离原有上传模块的复杂逻辑,以更简洁的资源管理模式(如避免使用全局缓存、强制在函数作用域内完成资源生命周期管理)重新实现核心上传逻辑,通过对比压测结果验证内存泄漏是否随代码结构调整而消失。
继续追踪问题
尽管内存增长现象因代码重构暂时消失,但根本原因仍成谜。通过日志回溯发现,504 错误触发的重试链路是唯一稳定的内存增长场景(因分布式竞争导致的 504 天然难以复现)。为构建可复现的测试环境,我们在重试逻辑中注入人工干预:前 5 次重试强制修改鉴权 Key(模拟上传必然失败),确保每次重试都触发 504 重试的完整链路。
- 测试方案设计:
- 内存数据隔离:所有测试文件均从内存缓冲区读取(避免磁盘 IO 干扰),确保每次上传的分片数据均为全新内存实例
- GC 行为控制:在每次上传完成后强制调用runtime.GC(),排除 GC 回收频率对内存观察的干扰
- 可视化监控:通过pprof+github.com/arl/statsviz搭建实时监控面板,同步展示:
- 堆内存分配热力图(按对象类型着色)
- 活跃 goroutine 数量曲线
- 特定分片结构体的实例存活数


问题定位
通过逐行断点调试与内存快照对比分析,最终精准定位到内存泄漏的源头。当删除该问题代码片段(如图所示)并重新压测后,实时监控的pprof内存分配图谱显示:持续增长的内存曲线立即回归平稳,各分片数据块在生命周期结束后被GC正常回收,此前因引用残留导致的内存堆积现象彻底消失。
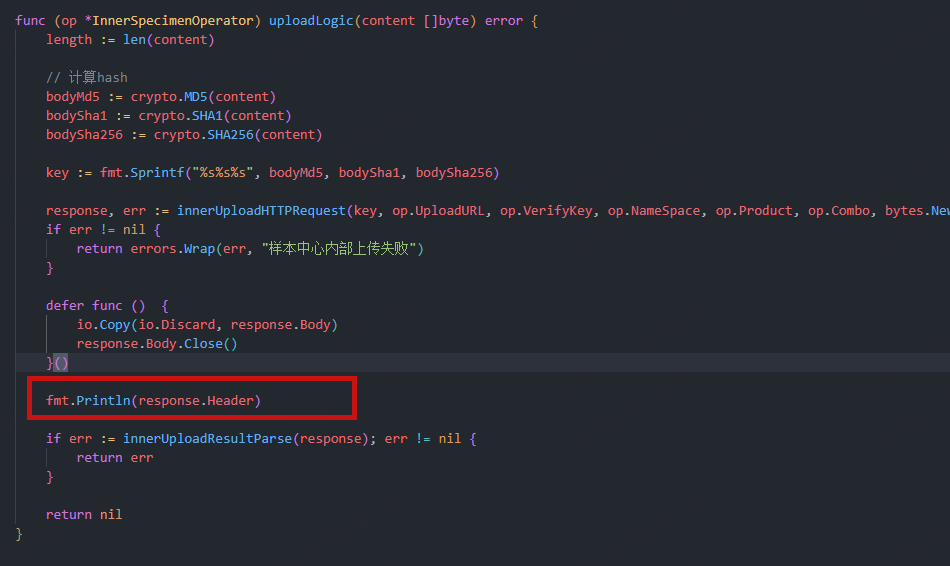
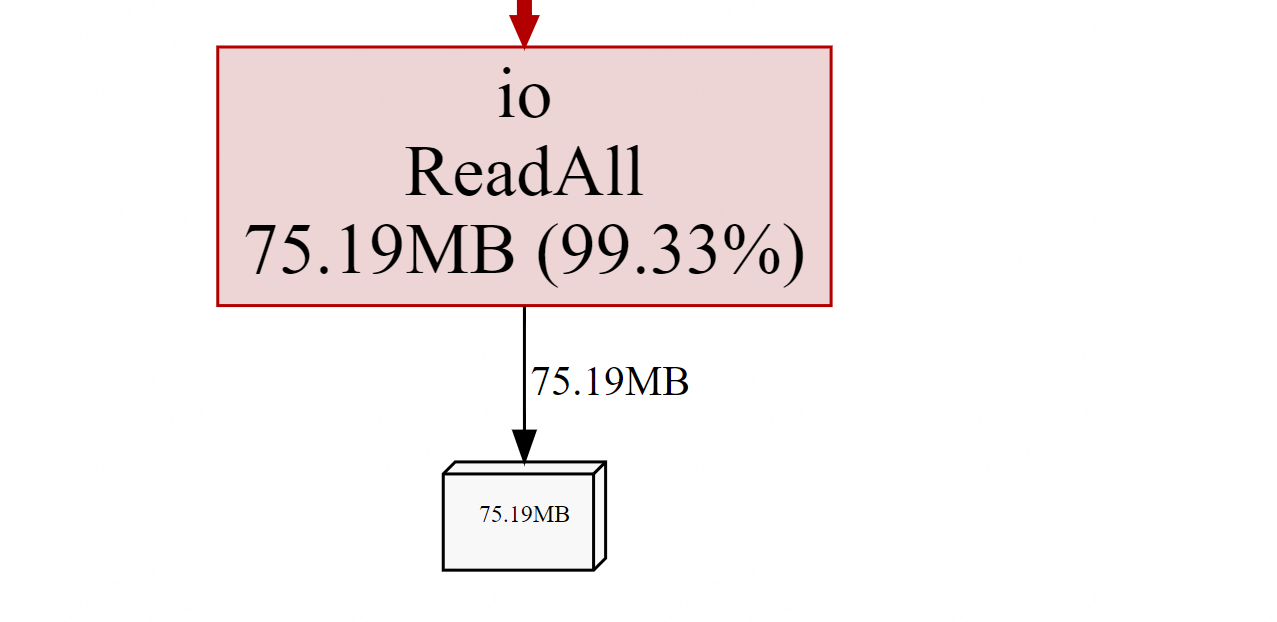
为验证问题是否与 Go 版本特性相关,我们对多个版本进行交叉测试:
- go1.21.x/1.22.x 全序列版本:均复现内存泄漏现象,且泄漏特征与问题代码强相关
- go1.20.x 及更早版本:因项目依赖限制未做完整测试
- go1.23.0 + 版本:无论怎么压测,内存曲线始终保持平稳
查阅 Go 1.23.0 的官方变更日志,发现唯一与 GC 相关的改动是:

尽管该优化未直接提及全局引用场景,但结合问题代码中「分片数据被全局上下文持有」的特征,推测可能与 GC 对非活跃全局变量的扫描策略优化有关。由于官方未明确说明此改动的影响范围,且我们的测试样本量有限,这个「版本间的偶然性修复」至今仍是未解之谜。或许是时候给 Go 团队提个GitHub Issue,附上完整的复现用例了。